Docker 快速启动 Hadoop
大约 6 分钟约 1862 字
Docker 快速启动 Hadoop
🎉 文章的主要目的就是为了快速启动一个 hadoop 环境,用于学习或者测试
当然首先需要 docker 环境,文章后面介绍了如何安装 docker
简单介绍一下镜像的基本信息
镜像大小 2G,服务包含 hadoop 和 hive,hive 配置了 spark 引擎
没有配 mysql,使用 hive 自带的 derby,有时间在搞
可以直接使用打好的镜像,或者尝试构建自己的镜像
启动 hiveserver2 10000 端口需要一些时间,耐心等待一会
版本信息
| 服务 | 版本 | 备注 |
|---|---|---|
| hadoop | 3.1.3 | |
| hive | 3.1.3 | 经过重新编译,用作 hive on spark |
| spark | 3.3.0 |
默认端口
可以修改,传递的环境变量会覆盖默认值
| 服务 | 端口 |
|---|---|
| hdfs web | 9870 |
| hdfs rpc | 8020 |
| yarn web | 8088 |
| history server | 19888 |
| hive metastore | 9083 |
| hiveserver2 | 10000 |
1 直接使用打包好的镜像
1.1 docker run
这里使用 host 网络,是为了更好的使用 web ui 的功能
修改 Windows 的 hosts 文件(我这里是 Windows,虚拟机用的 VMware),就可以愉快的玩耍了
docker run -itd \
--name hadoop100 \
--net=host \
-p 9870:9870 \
-p 8020:8020 \
-p 8088:8088 \
-p 19888:19888 \
-p 9083:9083 \
-p 10000:10000 \
registry.cn-hangzhou.aliyuncs.com/zhouwen/apache-hadoop:3.1.3
1.2 docker compose
执行步骤:
#首先需要创建一个文件夹
mkdir hadoop-compose && cd hadoop-compose
#创建hadoop.env文件
vi hadoop.env
#创建compose yml文件
vi docker-compose.yml
#启动
docker compose up -d
只有在 compose 才需要,docker run 有默认值
HADOOP_HDFS_NN_ADDRESS=namenode
HADOOP_YARN_RM_ADDRESS=resourcemanager
HADOOP_MR_HISTORYSERVER_ADDRESS=historyserver
HADOOP_HIVE_ADDRESS=hive
这里 replicated 3 表示这个服务会起 3 个副本,当然他还是单机
docker-compose.yml
version: '3.9'
services:
namenode:
image: registry.cn-hangzhou.aliyuncs.com/zhouwen/apache-hadoop:3.1.3
ports:
- 9870:9870
- 8020:8020
env_file:
- hadoop.env
healthcheck:
test: ['CMD-SHELL','curl -s namenode:9870 || exit 1']
interval: 30s
timeout: 2s
retries: 5
command: ['namenode']
datanode:
image: registry.cn-hangzhou.aliyuncs.com/zhouwen/apache-hadoop:3.1.3
depends_on:
namenode:
condition: service_healthy
restart: true
env_file:
- hadoop.env
command: ['datanode']
# deploy:
# mode: replicated
# replicas: 3
resourcemanager:
image: registry.cn-hangzhou.aliyuncs.com/zhouwen/apache-hadoop:3.1.3
ports:
- 8088:8088
env_file:
- hadoop.env
healthcheck:
test: ['CMD-SHELL','curl -s resourcemanager:8088 || exit 1']
interval: 30s
timeout: 2s
retries: 5
command: ['resourcemanager']
nodemanager:
image: registry.cn-hangzhou.aliyuncs.com/zhouwen/apache-hadoop:3.1.3
depends_on:
resourcemanager:
condition: service_healthy
restart: true
env_file:
- hadoop.env
command: ['nodemanager']
# deploy:
# mode: replicated
# replicas: 3
historyserver:
image: registry.cn-hangzhou.aliyuncs.com/zhouwen/apache-hadoop:3.1.3
ports:
- 19888:19888
depends_on:
resourcemanager:
condition: service_healthy
restart: true
env_file:
- hadoop.env
healthcheck:
test: ['CMD-SHELL','curl -s historyserver:19888 || exit 1']
interval: 30s
timeout: 2s
retries: 5
command: ['historyserver']
hive:
image: registry.cn-hangzhou.aliyuncs.com/zhouwen/apache-hadoop:3.1.3
ports:
- 9083:9083
- 10000:10000
depends_on:
namenode:
condition: service_healthy
restart: true
resourcemanager:
condition: service_healthy
restart: true
env_file:
- hadoop.env
healthcheck:
test: ['CMD-SHELL','curl -s hive:10000 || exit 1']
interval: 30s
timeout: 2s
retries: 5
command: ['hive']
2 尝试构建自己的镜像
2.1 安装 docker
#所需安装包
yum install -y yum-utils
#设置镜像仓库(阿里云)
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#更新yum软件包索引
yum makecache fast
#安装docker引擎
yum install docker-ce docker-ce-cli containerd.io
#设置阿里云镜像加速(登入阿里云控制台查看,貌似每个人都不一样)
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://jsodkx19.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
#查看是否安装成功
docker version
2.2 目录结构
注意
hadoop,jdk,hive,spark 这些需要自己下载
hive 需要自己编译,因为要适配高版本 spark 引擎
hadoop-compose/
├── docker-compose.yml
├── Dockerfile
├── hadoop.env
└── resource
├── bootstrap.sh
├── config
│ ├── core-site.xml
│ ├── hdfs-site.xml
│ ├── hive-site.xml
│ ├── mapred-site.xml
│ ├── spark-default.conf
│ ├── spark-env.sh
│ └── yarn-site.xml
├── hadoop-3.1.3.tar.gz
├── jdk-8u212-linux-x64.tar.gz
├── apache-hive-3.1.3-bin.tar.gz
└── spark-3.3.0-bin-without-hadoop.tgz
2.3 编写 dockerfile
Dockerfile
FROM centos:centos7
MAINTAINER 597879949@qq.com
# 时区
RUN ln -sfv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone
ENV LANG=zh_CN.UTF-8
# 工作目录
WORKDIR /opt
# 安装jdk
ADD ./resource/jdk-8u212-linux-x64.tar.gz /opt
ENV JAVA_HOME=/opt/jdk1.8.0_212
# 安装hadoop
ADD ./resource/hadoop-3.1.3.tar.gz /opt
ENV HADOOP_HOME=/opt/hadoop-3.1.3
ENV HADOOP_COMMON_HOME=${HADOOP_HOME}
ENV HADOOP_HDFS_HOME=${HADOOP_HOME}
ENV HADOOP_MAPRED_HOME=${HADOOP_HOME}
ENV HADOOP_YARN_HOME=${HADOOP_HOME}
ENV HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
# 安装hive
ADD ./resource/apache-hive-3.1.3-bin.tar.gz /opt
ENV HIVE_HOME=/opt/apache-hive-3.1.3-bin
# 安装spark
ADD ./resource/spark-3.3.0-bin-without-hadoop.tgz /opt
ENV SPARK_HOME=/opt/spark-3.3.0-bin-without-hadoop
# 默认值
ENV HADOOP_HDFS_NN_WEB_PORT=9870
ENV HADOOP_HDFS_NN_RPC_PORT=8020
ENV HADOOP_HDFS_2NN_PORT=9868
ENV HADOOP_YARN_RM_WEB_PORT=8088
ENV HADOOP_MR_HISTORYSERVER_WEB_PORT=19888
ENV HADOOP_MR_HISTORYSERVER_PRC_PORT=10020
ENV HADOOP_HIVE_METASTORE_PORT=9083
ENV HADOOP_HIVE_HIVESERVER2_PORT=10000
# 拷贝配置文件
RUN mkdir ${HADOOP_HOME}/data && mkdir ${HADOOP_HOME}/logs && mkdir /opt/config
COPY ./resource/config/* /opt/config
COPY ./resource/bootstrap.sh /opt
# 暴露端口
EXPOSE ${HADOOP_HDFS_NN_WEB_PORT}
EXPOSE ${HADOOP_HDFS_NN_RPC_PORT}
EXPOSE ${HADOOP_YARN_RM_WEB_PORT}
EXPOSE ${HADOOP_MR_HISTORYSERVER_WEB_PORT}
EXPOSE ${HADOOP_HIVE_METASTORE_PORT}
EXPOSE ${HADOOP_HIVE_HIVESERVER2_PORT}
ENTRYPOINT ["sh","./bootstrap.sh"]
CMD ["all"]
2.4 配置文件列表
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://${HADOOP_HDFS_NN_ADDRESS}:${HADOOP_HDFS_NN_RPC_PORT}</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>${HADOOP_HOME}/data</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>${HADOOP_HDFS_NN_ADDRESS}:${HADOOP_HDFS_NN_WEB_PORT}</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>${HADOOP_HDFS_NN_ADDRESS}:${HADOOP_HDFS_2NN_PORT}</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>${HADOOP_YARN_RM_ADDRESS}</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://${HADOOP_MR_HISTORYSERVER_ADDRESS}:${HADOOP_MR_HISTORYSERVER_WEB_PORT}/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>${HADOOP_MR_HISTORYSERVER_ADDRESS}:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>${HADOOP_MR_HISTORYSERVER_ADDRESS}:${HADOOP_MR_HISTORYSERVER_WEB_PORT}</value>
</property>
</configuration>
hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://${HADOOP_HIVE_ADDRESS}:${HADOOP_HIVE_METASTORE_PORT}</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>${HADOOP_HIVE_ADDRESS}</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>${HADOOP_HIVE_HIVESERVER2_PORT}</value>
</property>
<property>
<name>spark.yarn.jars</name>
<value>hdfs://${HADOOP_HDFS_NN_ADDRESS}:${HADOOP_HDFS_NN_RPC_PORT}/spark/spark-jars/*</value>
</property>
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
</configuration>
spark-env.sh
#!/usr/bin/env bash
export SPARK_DIST_CLASSPATH=$(${HADOOP_HOME}/bin/hadoop classpath)
spark-default.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://${HADOOP_HDFS_NN_ADDRESS}:${HADOOP_HDFS_NN_RPC_PORT}/spark/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
2.5 核心启动文件
bootstrap.sh
#!/bin/bash
set -euo pipefail
function print_title(){
echo -e "\n\n------------------------ $1 ------------------------"
}
function wait_for() {
echo Waiting for $1 to listen on $2...
while ! curl $1:$2 > /dev/null 2>&1; do echo waiting...; sleep 1s; done
}
function start_name_node(){
if [ ! -f /tmp/namenode-formated ];then
${HADOOP_HOME}/bin/hdfs namenode -format >/tmp/namenode-formated
fi
print_title "starting namenode"
${HADOOP_HOME}/bin/hdfs --loglevel INFO --daemon start namenode
print_title "starting secondarynamenode"
wait_for ${HADOOP_HDFS_NN_ADDRESS} ${HADOOP_HDFS_NN_WEB_PORT}
${HADOOP_HOME}/bin/hdfs --loglevel INFO --daemon start secondarynamenode
}
function start_data_node(){
print_title "starting datanode"
wait_for ${HADOOP_HDFS_NN_ADDRESS} ${HADOOP_HDFS_NN_WEB_PORT}
${HADOOP_HOME}/bin/hdfs --loglevel INFO --daemon start datanode
}
function start_resource_manager(){
print_title "starting resourcemanager"
${HADOOP_HOME}/bin/yarn --loglevel INFO --daemon start resourcemanager
}
function start_node_manager(){
print_title "starting nodemanager"
wait_for ${HADOOP_YARN_RM_ADDRESS} ${HADOOP_YARN_RM_WEB_PORT}
${HADOOP_HOME}/bin/yarn --loglevel INFO --daemon start nodemanager
}
function start_history_server(){
print_title "starting historyserver"
wait_for ${HADOOP_YARN_RM_ADDRESS} ${HADOOP_YARN_RM_WEB_PORT}
${HADOOP_HOME}/bin/mapred --loglevel INFO --daemon start historyserver
}
function start_hive() {
print_title "starting hive"
wait_for ${HADOOP_HDFS_NN_ADDRESS} ${HADOOP_HDFS_NN_WEB_PORT}
if [ ! -f /tmp/hive-formated ];then
${HADOOP_HOME}/bin/hdfs dfsadmin -safemode wait
${HADOOP_HOME}/bin/hdfs dfs -mkdir -p /spark/spark-history
${HADOOP_HOME}/bin/hdfs dfs -mkdir -p /spark/spark-jars
${HADOOP_HOME}/bin/hdfs dfs -put ${SPARK_HOME}/jars/* /spark/spark-jars
${HIVE_HOME}/bin/schematool -dbType derby -initSchema > /tmp/hive-formated
fi
nohup ${HIVE_HOME}/bin/hive --service metastore > ${HADOOP_HOME}/logs/metastore.log 2>&1 &
nohup ${HIVE_HOME}/bin/hive --service hiveserver2 > ${HADOOP_HOME}/logs/hiveserver2.log 2>&1 &
}
# The default value for a single container is hostname
export HADOOP_HDFS_NN_ADDRESS=${HADOOP_HDFS_NN_ADDRESS:-$(hostname)}
export HADOOP_YARN_RM_ADDRESS=${HADOOP_YARN_RM_ADDRESS:-$(hostname)}
export HADOOP_MR_HISTORYSERVER_ADDRESS=${HADOOP_MR_HISTORYSERVER_ADDRESS:-$(hostname)}
export HADOOP_HIVE_ADDRESS=${HADOOP_HIVE_ADDRESS:-$(hostname)}
{ echo 'cat << EOF' ; cat /opt/config/core-site.xml ; echo -e '\nEOF' ; } | sh > ${HADOOP_CONF_DIR}/core-site.xml
{ echo 'cat << EOF' ; cat /opt/config/hdfs-site.xml ; echo -e '\nEOF' ; } | sh > ${HADOOP_CONF_DIR}/hdfs-site.xml
{ echo 'cat << EOF' ; cat /opt/config/mapred-site.xml ; echo -e '\nEOF' ; } | sh > ${HADOOP_CONF_DIR}/mapred-site.xml
{ echo 'cat << EOF' ; cat /opt/config/yarn-site.xml ; echo -e '\nEOF' ; } | sh > ${HADOOP_CONF_DIR}/yarn-site.xml
{ echo 'cat << EOF' ; cat /opt/config/hive-site.xml ; echo -e '\nEOF' ; } | sh > ${HIVE_HOME}/conf/hive-site.xml
{ echo 'cat << EOF' ; cat /opt/config/spark-default.conf ; echo -e '\nEOF' ; } | sh > ${HIVE_HOME}/conf/spark-default.conf
cp /opt/config/spark-env.sh ${SPARK_HOME}/conf
case $1 in
all)
start_name_node
start_data_node
start_resource_manager
start_node_manager
start_history_server
start_hive
cd ${HADOOP_HOME}/logs
tail -f *.log | awk '/^==> / {fileName=substr($0,5,length-8); next} {printf("%-15s: %s\n",fileName,$0)}'
;;
namenode)
start_name_node
cd ${HADOOP_HOME}/logs
tail -f *namenode*.log *secondarynamenode*.log | awk '/^==> / {fileName=substr($0,5,length-8); next} {printf("%-15s: %s\n",fileName,$0)}'
;;
datanode)
start_data_node
tail -f ${HADOOP_HOME}/logs/*datanode*.log
;;
resourcemanager)
start_resource_manager
tail -f ${HADOOP_HOME}/logs/*resourcemanager*.log
;;
nodemanager)
start_node_manager
tail -f ${HADOOP_HOME}/logs/*nodemanager*.log
;;
historyserver)
start_history_server
tail -f ${HADOOP_HOME}/logs/*historyserver*.log
;;
hive)
start_hive
cd ${HADOOP_HOME}/logs
tail -f metastore.log hiveserver2.log | awk '/^==> / {fileName=substr($0,5,length-8); next} {printf("%-15s: %s\n",fileName,$0)}'
;;
*)
$@
;;
esac
2.6 构建镜像
#进入目录
cd hadoop-compose
#构建镜像
docker build -t hadoop100 .
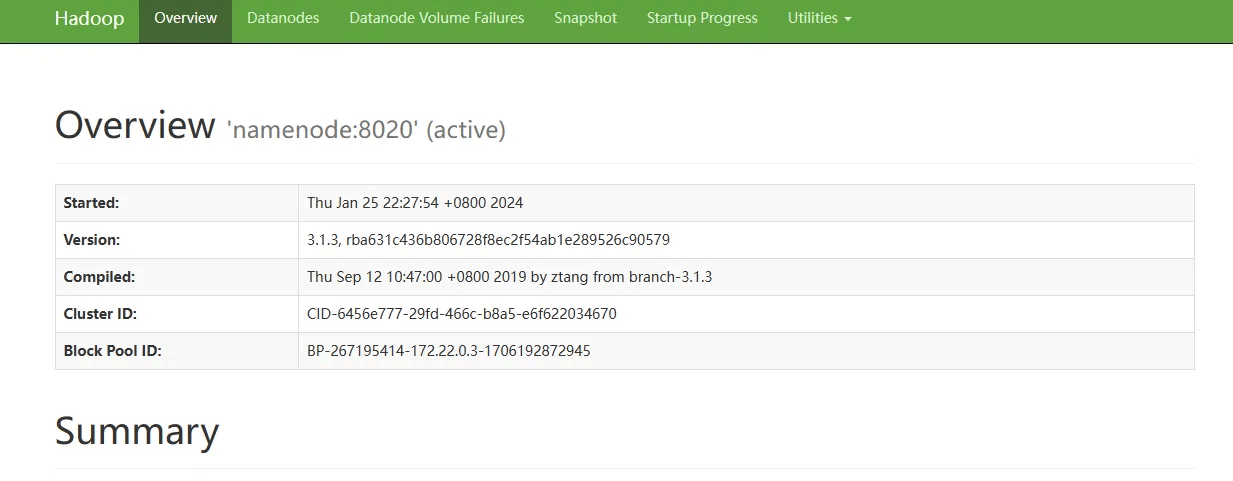
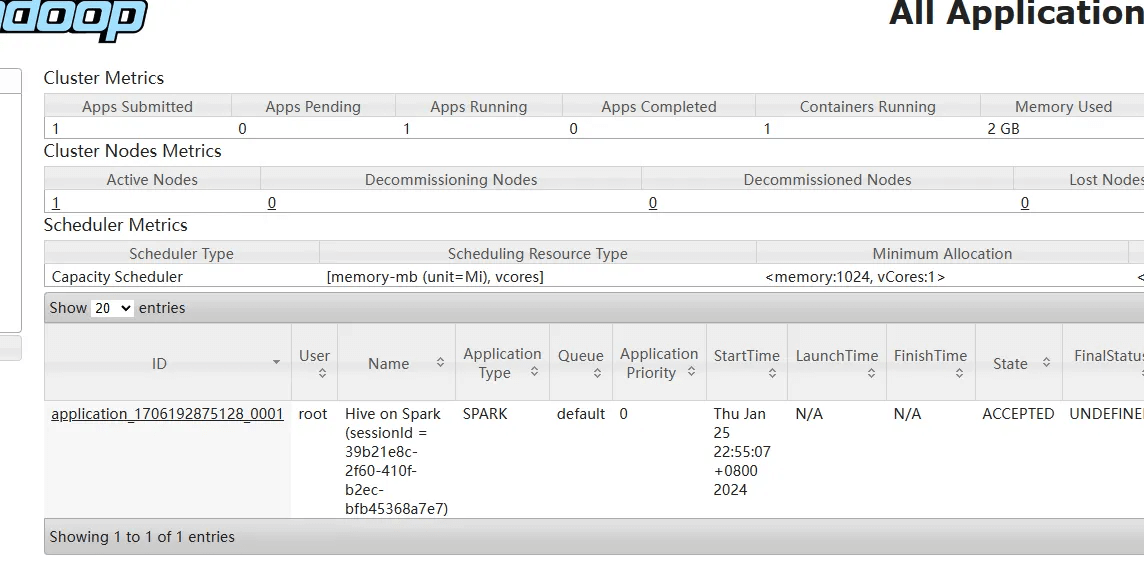
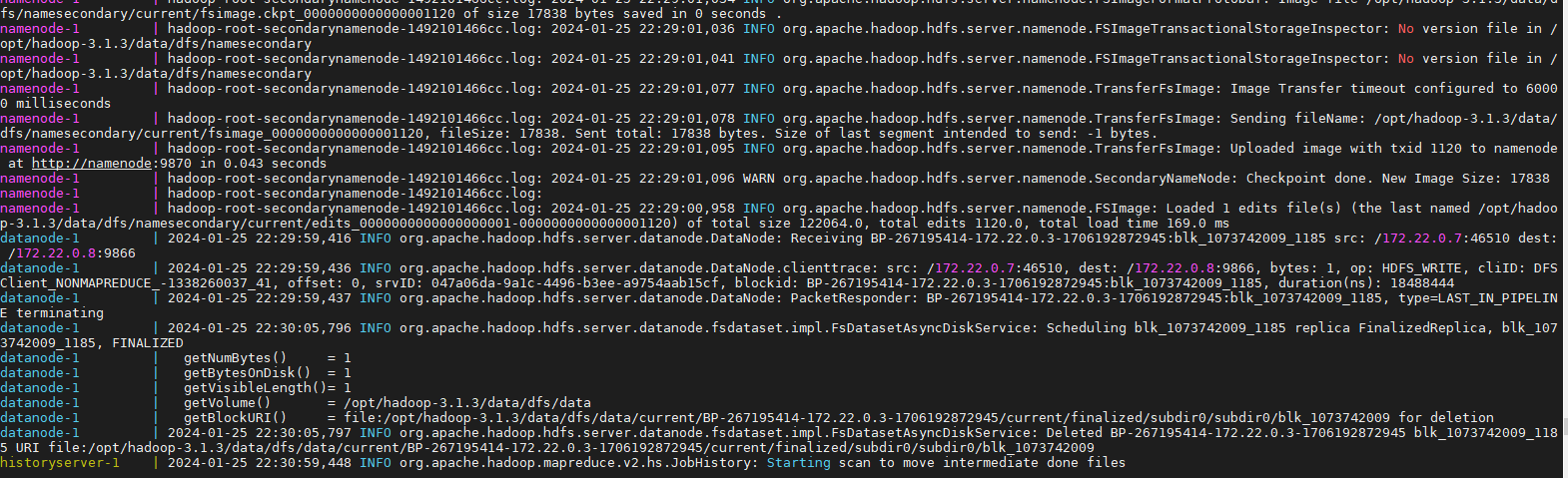
3 运行截图